هندسة أنظمة الوكلاء لـ GitHub Copilot و Cursor و Windsurf
%20by%20%E2%80%9EDiceBear%E2%80%9D%2C%20licensed%20under%20%E2%80%9ECC0%201.0%E2%80%9D%20(https%3A%2F%2Fcreativecommons.org%2Fpublicdomain%2Fzero%2F1.0%2F)%3C%2Fdc%3Arights%3E%3C%2Frdf%3ADescription%3E%3C%2Frdf%3ARDF%3E%3C%2Fmetadata%3E%3Cmask%20id%3D%22viewboxMask%22%3E%3Crect%20width%3D%2216%22%20height%3D%2216%22%20rx%3D%220%22%20ry%3D%220%22%20x%3D%220%22%20y%3D%220%22%20fill%3D%22%23fff%22%20%2F%3E%3C%2Fmask%3E%3Cg%20mask%3D%22url(%23viewboxMask)%22%3E%3Cpath%20d%3D%22M4%202h8v1h1v3h1v2h-1v3h-1v1H9v1h4v1h1v2H2v-2h1v-1h4v-1H4v-1H3V8H2V6h1V3h1V2Z%22%20fill%3D%22%23b68655%22%2F%3E%3Cpath%20d%3D%22M4%202h8v1h1v3h1v2h-1v3h-1v1H4v-1H3V8H2V6h1V3h1V2Z%22%20fill%3D%22%23fff%22%20fill-opacity%3D%22.1%22%2F%3E%3Cpath%20d%3D%22M13%207h1v2h-1zM2%207h1v2H2z%22%20fill%3D%22%23daa520%22%2F%3E%3Cpath%20d%3D%22M5%2013H4v3h3v-1H6v-1H5v-1ZM12%2013h-1v1h-1v1H9v1h3v-3Z%22%20fill%3D%22%2344c585%22%2F%3E%3Cpath%20fill%3D%22%23fff%22%20d%3D%22M4%205h3v2H4zM9%205h3v2H9z%22%2F%3E%3Cpath%20fill%3D%22%23876658%22%20d%3D%22M9%206h1v1H9zM4%206h1v1H4z%22%2F%3E%3Cpath%20d%3D%22M8%2010v1h1v-1H8Z%22%20fill%3D%22%23de0f0d%22%2F%3E%3Cpath%20d%3D%22M4%201v1H3v1H2v1H1v6h2V8H2V6h1V4h1V3h2v1h1V3h1V2H7V1H4Z%22%20fill%3D%22%2391cb15%22%2F%3E%3C%2Fg%3E%3C%2Fsvg%3E)
هندسة أنظمة الوكيل في GitHub Copilot و Cursor و Windsurf
في السنوات الأخيرة، ظهرت العديد من منتجات مساعد البرمجة بالذكاء الاصطناعي، مثل GitHub Copilot و Cursor و Windsurf. تقدم جميع تطبيقاتها مفهوم "الوكيل" (الوكيل الذكي)، مما يسمح للذكاء الاصطناعي بالمساعدة في أعمال البرمجة بشكل أكثر استباقية. يقدم هذا المقال مسحًا معمقًا لبناء نظام الوكيل لهذه المنتجات من منظور الهندسة المعمارية، بما في ذلك فلسفة التصميم المعماري، وتجزئة المهام والتخطيط، واستراتيجيات استدعاء النموذج، وإدارة حالة السياق، وآليات توسيع المكونات الإضافية، والمقايضات والابتكارات الرئيسية في تصاميمها الخاصة. يعتمد المحتوى التالي بشكل أساسي على المدونات الهندسية ا�لرسمية، ومقالات مطوري المشاريع، والمواد التقنية ذات الصلة.
بنية وكيل GitHub Copilot
فلسفة التصميم المعماري: وضع GitHub Copilot نفسه في البداية كـ "مبرمج مساعد بالذكاء الاصطناعي" للمطورين، وقد توسع الآن في هذا المفهوم بـ "وضع الوكيل" (Agent mode). نظام الوكيل الخاص به ليس مجموعة من الوكلاء المستقلين، بل هو وكيل ذكي مدمج يمكنه الانخراط في محادثات متعددة الأدوار وتنفيذ مهام متعددة الخطوات، ويدعم المدخلات متعددة الأنماط (على سبيل المثال، استخدام نماذج الرؤية لتفسير لقطات الشاشة). يؤكد Copilot على المساعدة بالذكاء الاصطناعي بدلاً من استبدال المطورين. في وضع الوكيل، يتصرف بشكل أشبه بمهندس آلي ضمن فريق، حيث يقبل المهام الموكلة إليه، ويكتب الكود بشكل مستقل، ويصحح الأخطاء، ويقدم النتائج عبر طلبات السحب (Pull Requests). يمكن تفعيل هذا الوكيل عبر واجهة الدردشة أو عن طريق تعيين مشكلة GitHub (GitHub Issue) إلى Copilot.
تحليل المهام والتخطيط: يتفوق وكيل Copilot في تقسيم مهام البرمجيات المعقدة إلى مهام فرعية وإكمالها واحدة تلو الأخرى، مستخدماً عملية استدلال داخلية مشابهة لـ "سلسلة التفكير" (Chain-of-Thought). إنه يتنقل بشكل متكرر عبر دورة "تحليل المشكلة ← تنفيذ تغييرات الكود أو الأوامر ← التحقق من النتائج" حتى يتم تلبية متطلبات المستخدم. على سبيل المثال، في وضع الوكيل، لا يقوم Copilot بتنفيذ الخطوات المحددة من قبل المستخدم فحسب، بل يستنتج وينفذ ضمنياً وبشكل تلقائي خطوات إضافية مطلوبة لتحقيق الهدف الرئيسي. إذا حدثت أخطاء في الترجمة/التجميع (compilation errors) أو إخفاقات في الاختبار (test failures) أثناء العملية، يقوم الوكيل بتحديد الأخطاء وإصلاحها بنفسه، ويحاول مرة أخرى، بحيث لا يضطر المطورون إلى تكرار نسخ ولصق رسائل الخطأ كتعليمات. تلخص مدونة VS Code دورة عمله: يحدد وكيل Copilot بشكل مستقل السياق والملفات ذات الصلة التي يجب تعديلها، ويقترح تعديلات الكود والأوامر التي يجب تشغيلها، ويراقب صحة التعديلات أو مخرجات الطرفية (terminal output)، ويكرر العملية باستمرار حتى تكتمل المهمة. يتيح هذا التنفيذ الآلي متعدد الأدوار لـ Copilot التعامل مع مجموعة متنوعة من المهام، من إنشاء تطبيق بسيط إلى إعادة هيكلة واسعة النطاق (large-scale refactoring) عبر ملفات متعددة.
استراتيجية استدعاء النموذج: كانت النماذج التي تقف وراء GitHub Copilot في البداية هي Codex من OpenAI، وقد تمت ترقيتها الآن إلى بنية متعددة النماذج (multi-model architecture) أكثر قوة. يتيح Copilot للمستخدمين تحديد نماذج أساسية مختلفة في "خيارات النموذج" (Model Options)، مثل GPT-4 من OpenAI (الاسم الرمزي الداخلي gpt-4o) ونسخته المبسطة، و Claude 3.5 من Anthropic (الاسم الرمزي Sonnet)، وأحدث نماذج Google Gemini 2.0 Flash، وغيرها. يعني هذا الدعم متعدد النماذج أن Copilot يمكنه تبديل مصادر النموذج بناءً على متطلبات المهمة أو تفضيلات المستخدم. في وظيفة Copilot Edits (تحرير الملفات المتعددة)، يستخدم GitHub أيضاً بنية ثنائية النماذج (dual-model architecture) لتحسين الكفاءة: أولاً، يقوم "النموذج الكبير" المختار بإنشاء خطة تحرير أولية بسياق كامل، ثم تقوم نقطة نهاية متخصصة لـ "فك التشفير التخميني" (speculative decoding) بتطبيق هذه التغييرات بسرعة. يمكن اعتبار فك التشفير التخميني نموذجاً خفيف الوزن أو محرك قواعد يقوم بإنشاء نتائج التحرير مسبقاً بينما يفكر النموذج الكبير في تغييرات الكود، وبالتالي يقلل من زمن الاستجابة. باختصار، تتمثل استراتيجية نموذج Copilot في دمج نماذج لغة كبيرة (LLMs) متعددة ومتطورة في السحابة، محسّنة لسيناريوهات مختلفة، وتحقيق التوازن بين سرعة الاستجابة والدقة من خلال الوسائل الهندسية (مسار ثنائي النماذج).
إدارة الحالة والاحتفاظ بالسياق: يولي وكيل Copilot أهمية كبيرة للاستفادة من سياق التطوير. نظراً لأن توفير كود المستودع بأكمله مباشرة كمدخل للنماذج الكبيرة غير عملي، يستخدم Copilot استراتيجية التوليد المعزز بالاسترجاع (RAG): يبحث عن المحتوى ذي الصلة داخل المستودع باستخدام أدوات مثل GitHub Code Search ويقوم بحقن مقتطفات الكود المسترجعة ديناميكياً في سياق النموذج. عندما يبدأ الوكيل، يقوم باستنساخ كود المشروع في بيئة معزولة ويحلل أولاً بنية قاعدة الكود، ويولد ملخصات ضرورية لتوفير الرموز (tokens). على سبيل المثال، قد يتضمن التوجيه الذي ينشئه Copilot "ملخص بنية ملف المشروع + محتوى الملفات الرئيسية + طلب المستخدم". يتيح ذلك للنموذج فهم الصورة الكلية عند إنشاء الحلول دون تجاوز حدود طول السياق. أثناء المحادثات، يتتبع Copilot أيضاً سجل الجلسة (session history) (على سبيل المثال، التعليمات التي قدمها المستخدم مسبقاً في الدردشة) للحفاظ على الاستمرارية. في الوقت نفسه، يتكامل Copilot بعمق مع منصة GitHub، مما يتيح له استخدام أوصاف المشكلات (issue descriptions)، ومناقشات طلبات السحب (PR discussions) ذات الصلة، وما إلى ذلك، كسياق إضافي. على وجه التحديد، إذا كان المستودع يحتوي على ملفات تكوين تحدد معايير الترميز أو تعليمات سابقة لاستخدام الذكاء الاصطناعي، فسيلتزم الوكيل أيضاً بهذه التعليمات المخصصة للمستودع. من المهم ملاحظة أن Copilot نفسه لا يمتلك ذاكرة طويلة الأمد لكود المستخدم — فهو لا يحفظ الحالة تلقائياً بعد كل جلسة للجلسة التالية (ما لم يتم ترميزها بشكل ثابت من قبل المستخدم في الوثائق). ومع ذلك، من خلال آليات GitHub للمشكلات/طلبات السحب، يمكن للمستخدمين توفير أوصاف مهام ولقطات شاشة مستمرة للوكيل بشكل فعال، والتي يمكن اعتبارها وسيلة لحمل السياق.
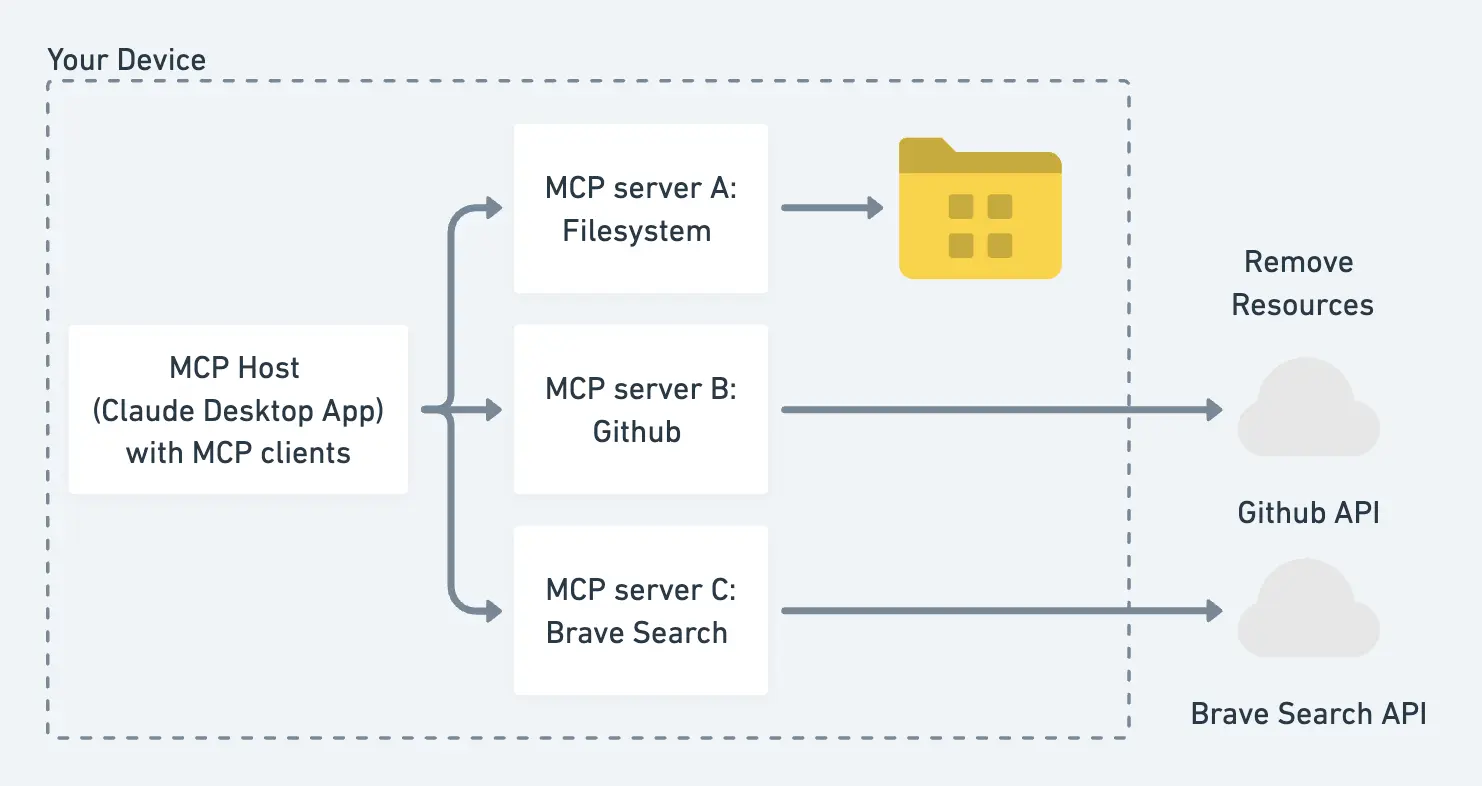
نظام المكونات الإضافية وآلية التوسيع: يقوم وكيل GitHub Copilot بعمليات على بيئة التطوير المتكاملة (IDE) والبيئة الخارجية من خلال استدعاءات الأدوات (Tool Use). من ناحية، في البيئات المحلية أو Codespaces، يمكن لـ Copilot استدعاء واجهات برمجة التطبيقات (APIs) التي توفرها إضافات VS Code لأداء عمليات مثل قراءة الملفات، وفتح المحررات، وإدراج مقتطفات الكود، وتشغيل أوامر الطرفية. من ناحية أخرى، قدمت GitHub بروتوكول سياق النموذج (MCP) لتوسيع "رؤية" وقدرات الوكيل. يسمح MCP بتكوين "خوادم موارد" خارجية، ويمكن للوكيل طلب بيانات أو عمليات إضافية من خلال واجهة موحدة. على سبيل المثال، توفر GitHub رسمياً خادم MCP الخاص بها، مما يسمح للوكيل بالحصول على مزيد من المعلومات حول المستودع الحالي (مثل نتائج بحث الكود، ويكي المشروع، إلخ). تدعم آلية MCP أيضاً الأطراف الثالثة: طالما أنها تنفذ واجهة MCP، يمكن للوكيل الاتصال بها، مثل استدعاء خدمات استعلام قواعد البيانات أو إرسال طلبات HTTP. يمتلك وكيل Copilot بالفعل بعض القدرات متعددة الأنماط. من خلال التكامل مع نماذج الرؤية، يمكنه تحليل لقطات الشاشة، ورسوم التصميم البيانية، والصور الأخرى المرفقة من قبل المستخدمين في المشكلات كمدخلات مساعدة. هذا يعني أنه عند تصحيح أخطاء واجهة المستخدم (UI issues) أو استنساخ الأخطاء، يمكن للمطورين توفير لقطات شاشة لـ Copilot، ويمكن للوكيل "التحدث من الصور" لتقديم اقتراحات تعديل الكود المقابلة. علاوة على ذلك، بعد إكمال المهمة، يقوم وكيل Copilot تلقائياً بتثبيت التغييرات عبر Git ويفتح طلب سحب مسودة (Draft PR)، ثم يشير (@mentions) إلى المطورين المعنيين لطلب مراجعة. يتم أيضاً قراءة تعليقات وملاحظات المراجعين (مثل طلب تعديل تنفيذ معين) بواسطة الوكيل وتعمل كتعليمات جديدة، مما يؤدي إلى جولة جديدة من تحديثات الكود. تشبه العملية بأكملها تعاون المطورين البشريين: وكيل الذكاء الاصطناعي يقدم الكود ← البشر يراجعون ويقدمون الملاحظات ← وكيل الذكاء الاصطناعي يقوم بالتحسين، مما يضمن أن البشر لديهم دائماً السيطرة.
المقايضات والابتكارات الرئيسية في التصميم: يستفيد نظام وكيل GitHub Copilot بشكل كامل من نظام بيئة منصة GitHub الحالي، وهي سمة مهمة له. من ناحية، يختار إنشاء بيئة تنفيذ الكود على حاويات سحابة GitHub Actions، مما يحقق عزلاً جيداً وقابلية للتوسع. "Project Padawan" هو الاسم الرمزي لهذه البنية، والتي تتجنب بناء بنية تحتية جديدة للتنفيذ من الصفر وبدلاً من ذلك تبني على نظام تكامل مستمر/نشر مستمر (CI/CD) ناضج. من ناحية أخرى، يقوم Copilot بمقايضات صارمة فيما يتعلق بالأمان: بشكل افتراضي، يمكن للوكيل فقط دفع الكود إلى الفروع التي تم إنشاؤها حديثاً، ولا يمكنه تعديل الفرع الرئيسي مباشرة، ويجب الموافقة على طلبات السحب التي يتم تشغيلها من قبل الآخرين قبل الدمج، ويتم إيقاف مسارات CI مؤقتاً قبل الموافقة. تضمن هذه الاستراتيجيات أن إدخال الأتمتة بالذكاء الاصطناعي لا يعطل نظام المراجعة وبوابات الإصدار الحالية للفريق. يمكن اعتبار اقتراح بروتوكول سياق النموذج ابتكاراً هندسياً مهماً لـ Copilot — فهو يحدد معياراً مفتوحاً لوكلاء نماذج اللغة الكبيرة (LLM Agents) للوصول إلى الأدوات/البيانات الخارجية، مما يسمح بدمج مصادر البيانات المختلفة، داخل وخارج GitHub، بسلاسة في توجيهات الذكاء الاصطناعي في المستقبل. بالإضافة إلى ذلك، يسجل وكيل Copilot سجلات التفكير (session logs) أثناء التنفيذ، بما في ذلك الخطوات التي يتخذها لاستدعاء الأدوات والمخرجات التي يولدها، ويقدم هذه السجلات للمطور. تتيح هذه الشفافية للمستخدمين مراجعة "أفكار" وإجراءات الوكيل، مما يسهل تصحيح الأخطاء وبناء الثقة. بشكل عام، يدمج GitHub Copilot وكلاء الذكاء الاصطناعي في مراحل مختلفة من دورة حياة التطوير (الترميز -> تقديم طلب السحب -> مراجعة الكود)، ومن خلال سلسلة من القرارات المعمارية، يحقق تكاملاً سلساً للأتمتة مع سير العمل الحالي.
هندسة وكيل Cursor
فلسفة التصميم المعماري: Cursor هو أداة برمجة مدعومة بالذكاء الاصطناعي تم تطويرها بواسطة الشركة الناشئة Anysphere. إنه في الأساس محرر أكواد (معدل بناءً على VS Code) مدمج بعمق مع مساعد ذكاء اصطناعي. يقدم Cursor وضعين رئيسيين للتفاعل: مساعد الدردشة والوكيل المستقل. في وضع المحادثة العادي، يعمل كمساعد أكواد تقليدي، يجيب على الأسئلة أو يولد الأكواد بناءً على التعليمات؛ وعند التبديل إلى وضع الوكيل (المعروف أيضًا باسم "Composer")، يمكن لـ Cursor تنفيذ سلسلة من العمليات بشكل استباقي نيابة عن المطور. تمنح هذه الهندسة المستخدمين حرية الاختيار حسب الحاجة: يمكن التعامل مع المهام البسيطة عن طريق السؤال سطرًا بسطر في وضع المساعد، بينما يمكن معالجة المهام المعقدة أو المتكررة دفعة واحدة عن طريق استدعاء الوكيل. يركز Cursor حاليًا بشكل أساسي على المساعدة في مجال النص (التعليمات البرمجية)، دون التركيز على الإدخال/الإخراج متعدد الوسائط (على الرغم من أنه يوفر وظيفة الإدخال الصوتي، وتحويل الكلام إلى نص للمطالبات). على غرار Copilot، يعمل نظام وكيل Cursor أيضًا كوكيل ذكي واحد على التوالي، وليس وكلاء متعددين يعملون بالتوازي. ومع ذلك، فإن ميزته المميزة هي تركيزه على التعاون بين الإنسان والذكاء الاصطناعي: في وضع الوكيل، يتخذ الذكاء الاصطناعي أكبر عدد ممكن من الإجراءات، ولكنه بشكل عام لا يزال يسمح للمطورين بالتدخل والتحكم في أي وقت، بدلاً من العمل دون إشراف كامل لفترات طويلة.
تجزئة المهام والتخطيط: في وضع وكيل Cursor، يمكن للذكاء الاصطناعي التعامل مع المهام المعقدة عبر الملفات، ولكن التصميم يميل نحو أسلوب الطلب خطوة بخطوة. بعد تلقي تعليمات عالية المستوى من المستخدم، يقوم الوكيل بالبحث بشكل مستقل عن مقتطفات التعليمات البرمجية ذات الصلة، ويفتح الملفات التي تحتاج إلى تعديل، ويولد خطط التعديل، وحتى يقوم بتشغيل أوامر الاختبار/البناء للتحقق من التأثير. ومع ذلك، على عكس وكلاء Copilot أو Windsurf، يتوقف وكيل Cursor عادةً بعد إكمال اقتراح أولي، في انتظار مراجعة المستخدم وتعليمات إضافية. هذا يعني أن وكيل Cursor لا يقوم عادةً بتحسين نفسه بشكل مستمر ومتكرر ما لم يتلقى مطالبة جديدة من المستخدم. على سبيل المثال، إذا طلبت من Cursor إجراء إعادة هيكلة عبر المشاريع، فسيقوم بجمع جميع المواقع التي تحتاج إلى تعديل وإنشاء فرق لكل ملف ليراجعه المستخدم؛ في هذه المرحلة، يقرر المستخدم التغييرات التي يجب قبولها وتطبيقها. إذا أدت هذه التغييرات إلى مشاكل جديدة، فلن يستمر Cursor في التعديل بشكل تعسفي ما لم يقدم المستخدم طلبات إضافية مثل "إصلاح المشاكل التي ظهرت". تضمن هذه الآلية الإشراف البشري عند نقاط القرار الحرجة، مما يمنع الذكاء الاصطناعي من العمل بشكل جامح. ومع ذلك، فهذا يعني أيضًا أن وكيل Cursor يفتقر إلى الاستقلالية في التخطيط طويل السلسلة، ويتطلب توجيهًا بشريًا خطوة بخطوة لإكمال حلقات مغلقة معقدة. لتحسين الاستقلالية المستمرة جزئيًا، أضاف فريق Cursor أيضًا بعض الميزات التكرارية إلى نظام الوكيل. على سبيل المثال، سيحاول تجميع التعليمات البرمجية وتشغيلها واكتشاف الأخطاء، وإصلاح بعض المشاكل البسيطة تلقائيًا مثل أخطاء بناء الجملة أو أخطاء التدقيق اللغوي، ولكنه يتوقف عادةً بعد بضع محاولات، ويعيد التحكم إلى المستخدم. لاحظ المطورون أن وكيل Cursor يعمل بكفاءة عالية في إعادة الهيكلة المحلية أو التغييرات ذات النطاق المحدود، ولكن بالنسبة للتغييرات واسعة النطاق، فإنه غالبًا ما يتطلب من المستخدم المطالبة في أجزاء، وإكمال المهمة خطوة بخطوة. بشكل عام، يضع Cursor الوكيل كـ "مساعد تنفيذ ذكي" بدلاً من روبوت برمجة آلي كلي القدرة؛ يميل تخطيط مهامه نحو التنفيذ قصير المدى، والإبلاغ في الوقت المناسب، وترك البشر يقررون الخطوة التالية.
استراتيجية استدعاء النموذج: لا يقوم Cursor بتدريب نماذجه اللغوية الكبيرة الخاصة به؛ بل يتبنى استراتيجية دمج واجهات برمجة التطبيقات (APIs) التابعة لجهات خارجية. يمكن للمستخدمين تكوين مفاتيح API من بائعين مثل OpenAI أو Anthropic داخل Cursor، ثم يقوم الواجهة الخلفية لـ Cursor باستدعاء النموذج الكبير المقابل نيابة عن المستخدم. بغض النظر عن مزود النموذج الذي يختاره المستخدم، ستمر جميع طلبات الذكاء الاصطناعي عبر خادم Cursor الخاص: يقوم التطبيق المحلي بتجميع سياق المحرر وأسئلة المستخدم ويرسلها إلى السحابة، يقوم خادم Cursor بتجميع المطالبة الكاملة واستدعاء النموذج، ثم يعيد النتائج إلى المحرر. تسهل هذه الهندسة على Cursor تحسين المطالبات والإدارة الموحدة لحالات الجلسة، ولكنها تعني أيضًا أنه يجب استخدامه عبر الإنترنت، وأن وظائف الذكاء الاصطناعي الأساسية غير متاحة في وضع عدم الاتصال. لاعتبارات تكلفة المطور، يدعم Cursor المستخدمين الذين يستخدمون حصص API الخاصة بهم (لذا يتم فوترة استدعاء النموذج للمستخدم)، ولكن حتى في هذه الحالة، لا تزال الطلبات تمر عبر الخادم الرسمي لعمليات مثل استرجاع تضمين التعليمات البرمجية وتنسيق الاستجابة. فيما يتعلق باختيار النموذج، يقدم Cursor عادةً عددًا قليلاً من النماذج السائدة للاختيار من بينها (مثل GPT-4، GPT-3.5، Claude 2، وما إلى ذلك)؛ يمكن للمستخدمين تفضيل واحد، ولكن لا يمكنهم الوصول إلى النماذج غير المدعومة بواسطة Cursor. على النقيض من ذلك، تسمح أنظمة مثل Windsurf باستبدال المحرك الأساسي، بينما Cursor أكثر إغلاقًا، حيث يتم التحكم في تحديثات النموذج وتعديلاته بشكل أساسي من قبل الفريق الرسمي. بالإضافة إلى ذلك، لا يمتلك Cursor حلول نشر محلية مثل Copilot Enterprise، ولا يدمج نماذج مفتوحة المصدر - إنه موجه بالكامل نحو الخدمات السحابية، لذا يمكنه مواكبة أحدث إصدارات النماذج الكبيرة بسرعة، ولكنه يتطلب أيضًا من المستخدمين الوثوق بمعالجته السحابية والامتثال لسياسات الخصوصية ذات الصلة. تجدر الإشارة إلى أن Cursor يوفر "وضع التفكير"؛ ووفقًا لتعليقات المستخدمين، فإن تمكينه يجعل استجابات الذكاء الاصطناعي أكثر عمقًا وصرامة، مما قد يعني التحول إلى نموذج أكثر قوة أو إعدادات مطالبة خاصة، ولكن التفاصيل التنفيذية المحددة لم يتم توضيحها من قبل الفريق الرسمي.
إدارة الحالة والاحتفاظ بالسياق: لتعزيز فهمه للمشروع بأكمله، يقوم Cursor بمعالجة قاعدة التعليمات البرمجية مسبقًا محليًا أو في السحابة: يقوم بحساب تضمينات المتجهات لجميع الملفات وبناء فهرس دلالي لدعم البحث الدلالي ومطابقة الصلة. بشكل افتراضي، عند فتح مشروع جديد، يقوم Cursor تلقائيًا بتحميل مقتطفات التعليمات البرمجية على دفعات إلى الخادم السحابي لإنشاء تضمينات وحفظها (يخزن فقط متجهات التضمين وتجزئات الملفات، وليس التعليمات البرمجية النصية العادية). بهذه الطريقة، عندما يطرح المستخدمون أسئلة حول التعليمات البرمجية، يمكن لـ Cursor البحث عن الملفات أو المقتطفات ذات الصلة في مساحة التضمين واستخراج محتواها لتزويد النموذج بها كمرجع، دون الحاجة إلى تغذية قاعدة التعليمات البرمجية بأكملها في المطالبة. ومع ذلك، نظرًا لمحدودية نافذة سياق النموذج (الآلاف إلى عشرات الآلاف من الرموز)، فإن استراتيجية Cursor هي التركيز على السياق الحالي: أي، السماح للنموذج بالتركيز بشكل أساسي على الملف الذي يقوم المستخدم بتحريره حاليًا، أو الجزء المحدد من التعليمات البرمجية، أو المقتطفات التي يوفرها المستخدم بنشاط. يحتوي Cursor على نقطة دخول "يعرف قاعدة التعليمات البرمجية الخاصة بك" تسمح لك بالسؤال عن محتوى الملفات غير المفتوحة؛ وهذا في الأساس يقوم بإجراء بحث دلالي في الخلفية ويدرج المحتوى ذي الصلة الذي تم العثور عليه في المطالبة. بعبارة أخرى، إذا كنت تريد أن يأخذ الذكاء الاصطناعي في الاعتبار جزءًا معينًا من التعليمات البرمجية، فعادة ما تحتاج إلى فتح هذا الملف أو لصقه في المحادثة؛ وإلا، فلن يقوم Cursor افتراضيًا بتغذية النموذج بالكثير من محتوى الملفات "غير ذات الصلة". تضمن إدارة السياق هذه أن تكون الإجابات مركزة بدقة، ولكنها قد تفوت الارتباطات الضمنية عبر الملفات في المشروع، ما لم يدرك المستخدم ذلك ويطالب الذكاء الاصطناعي باسترجاعها. لمعالجة مشكلة الذاكرة طويلة المدى، يوفر Cursor آلية قواعد المشروع. يمكن للمطورين إنشاء ملفات .cursor/rules/*.mdc لتسجيل معرفة المشروع الهامة، أو معايير الترميز، أو حتى تعليمات محددة، وسيقوم Cursor تلقائيًا بتحميل هذه القواعد كجزء من مطالبة النظام عند تهيئة كل جلسة. على سبيل المثال، يمكنك إنشاء قاعدة مثل "يجب أن تسجل جميع وظائف API"، وسيتتبع Cursor هذا الاتفاق عند إنشاء التعليمات البرمجية - أبلغ بعض المستخدمين أنه من خلال التراكم المستمر لتجربة المشروع في ملفات القواعد، يتحسن فهم Cursor واتساقه مع المشروع بشكل كبير. هذه الملفات القاعدية تعادل الذاكرة طويلة المدى التي يمنحها المطور للوكيل، ويتم صيانتها وتحديثها بواسطة البشر (يمكن أيضًا أن يُطلب من Cursor "إضافة استنتاجات هذه المحادثة إلى القواعد"). بالإضافة إلى ذلك، يدعم Cursor استمرارية سياق سجل المحادثة: ضمن نفس الجلسة، يتم تمرير الأسئلة السابقة التي طرحها المستخدم والإجابات التي قدمها Cursor إلى النموذج كجزء من سلسلة المحادثة، مما يضمن الاتساق في التواصل متعدد الأدوار. ومع ذلك، لا يتذكر Cursor حاليًا المحادثات السابقة تلقائيًا عبر الجلسات (ما لم يتم حفظها في ملفات القواعد المذكورة أعلاه)؛ تبدأ كل جلسة جديدة من الصفر بقواعد المشروع + السياق الحالي.
نظام المكونات الإضافية وآلية التوسع: يمكن لوكيل Cursor استدعاء عمليات مشابهة لـ Copilot، ولكن نظرًا لأن Cursor نفسه بيئة تطوير متكاملة (IDE) كاملة، فإن تكامل أدواته مدمج بشكل أكبر. على سبيل المثال، يحدد Cursor أدوات مثل open_file، read_file، edit_code، run_terminal، وما إلى ذلك، ويصف غرضها واستخدامها بالتفصيل في مطالبة النظام. تم ضبط هذه الأوصاف بدقة من قبل الفريق لضمان أن النموذج اللغوي الكبير (LLM) يعرف متى يستخدم الأداة الصحيحة في السياق الصحيح. ذكرت مدونة Anthropic الرسمية ذات مرة أن تصميم مطالبات فعالة لتعليم النموذج كيفية استخدام الأدوات هو فن بحد ذاته، وقد بذل Cursor بوضوح الكثير من الجهد في هذا. على سبيل المثال، ينص Cursor صراحة في مطالبة النظام: "لا تقم بإخراج مقتطفات التعليمات البرمجية الكاملة مباشرة للمستخدم؛ بدلاً من ذلك، قم بتقديم التعديلات عبر edit_tool" لمنع الذكاء الاصطناعي من تجاوز الأداة وطباعة كتل نصية كبيرة مباشرة. مثال آخر هو: "قبل استدعاء كل أداة، اشرح للمستخدم في جملة واحدة سبب قيامك بذلك،" حتى لا يعتقد المستخدم خطأً أن الذكاء الاصطناعي قد تجمد عندما يقوم بعملية "صامتة" لفترة طويلة. تعزز هذه التصميمات التفصيلية تجربة المستخدم وثقته. بالإضافة إلى الأدوات المدمجة، يدعم Cursor أيضًا تركيب "المكونات الإضافية" الإضافية عبر بروتوكول سياق النموذج (MCP). من منظور هندسي، ينظر Cursor إلى MCP كواجهة قياسية لتوسيع قدرات الوكيل: يمكن للمطورين كتابة خدمة وفقًا لمواصفات MCP ليقوم Cursor باستدعائها، وبالتالي تحقيق وظائف مختلفة مثل الوصول إلى قواعد البيانات، أو استدعاء واجهات برمجة التطبيقات الخارجية، أو حتى التحكم في المتصفحات. على سبيل المثال، شارك بعض مستخدمي المجتمع في دمج قاعدة بيانات المتجهات الخاصة بـ OpenAI عبر MCP لتخزين واسترجاع معرفة المشروع طويلة المدى، مما يضيف بشكل فعال "ذاكرة طويلة المدى" إلى وكيل Cursor. من المهم ملاحظة أن خدمات MCP يتم إطلاقها عادةً محليًا أو في سحابة خاصة. يعرف Cursor عناوين هذه الخدمات والتعليمات المتاحة من خلال ملفات التكوين، ثم يمكن للنموذج استدعائها بناءً على قائمة الأدوات المتوفرة في مطالبة النظام. باختصار، تمنح آلية المكونات الإضافية في Cursor وكيلها درجة معينة من قابلية البرمجة، مما يسمح للمستخدمين بتوسيع قدرات الذكاء الاصطناعي.
المقايضات والابتكارات الرئيسية في التصميم: كمنتج بيئة تطوير متكاملة (IDE)، اتخذ Cursor مقايضات مختلفة في تصميم نظام الوكيل مقارنة بـ GitHub Copilot. أولاً، اختار بنية تنفيذ قائمة على السحابة، مما يعني أن المستخدمين لا يحتاجون إلى إعداد قوة حوسبة محلية للاستفادة من نماذج الذكاء الاصطناعي القوية، ويمكن لـ Cursor ترقية وتحسين وظائف الواجهة الخلفية بشكل موحد. التكلفة هي أن المستخدمين يجب أن يثقوا في خدماته السحابية ويقبلوا زمن انتقال الشبكة، لكن Cursor يوفر بعض الضمانات من خلال "وضع الخصوصية" (الذي يعد بعدم تخزين كود المستخدم وسجل الدردشة على المدى الطويل). ثانيًا، فيما يتعلق بالتفاعل مع النماذج، يؤكد Cursor على أهمية هندسة المطالبات. كما أوضح المطورون، يقوم مطالبة نظام Cursor بإعداد العديد من القواعد بدقة، من عدم الاعتذار في الصياغة إلى تجنب الإشارات الوهمية إلى أدوات غير موجودة - يتم أخذ تفاصيل مختلفة في الاعتبار. تؤثر هذه الإرشادات المخفية بشكل كبير على جودة واتساق سلوك استجابات الذكاء الاصطناعي. هذا "الضبط العميق" بحد ذاته ابتكار هندسي: لقد وجد فريق Cursor مجموعة من نماذج المطالبات من خلال التجريب المستمر التي تحول النماذج اللغوية الكبيرة للأغراض العامة إلى "خبراء في البرمجة"، ويقوم بتعديلها باستمرار مع تطور إصدارات النماذج. ثالثًا، يتبنى Cursor استراتيجية محافظة في تقسيم العمل بين الإنسان والآلة - يفضل أن يقوم الذكاء الاصطناعي بعمل أقل قليلاً على ضمان أن يكون المستخدم على دراية دائمًا. على سبيل المثال، يستخدم كل تغيير رئيسي قائمة فروق للمستخدم للتأكيد، على عكس بعض الوكلاء الذين يقومون بتعديل التعليمات البرمجية مباشرة ثم يخبرونك "لقد تم الأمر". يقرر هذا القرار المنتج عدم كمال الذكاء الاصطناعي الحالي والحاجة إلى الإشراف البشري. على الرغم من أنه يضحي ببعض كفاءة الأتمتة، إلا أنه يكسب موثوقية أعلى وقبولًا من المستخدم. أخيرًا، تجدر الإشارة إلى نهج Cursor في قابلية التوسع: استخدام قواعد المشروع للسماح للمستخدمين بتعويض أوجه القصور في السياق والذاكرة، واستخدام مكونات MCP الإضافية للسماح للمستخدمين المتقدمين بتوسيع قدرات الذكاء الاصطناعي. توفر هذه التصميمات للمستخدمين مساحة تخصيص عميقة وهي الأساس لتكيفها المرن مع الفرق والمهام المختلفة. في مجال مساعدي الذكاء الاصطناعي شديد التنافسية، لا يسعى Cursor إلى تحقيق أقصى قدر من الأتمتة الشاملة، بل يبني منصة مساعد ذكاء اصطناعي عالية المرونة يمكن تدريبها من قبل المطورين، وهي ميزة رئيسية لفلسفته الهندسية.
بنية وكيل Windsurf (Codeium)
فلسفة التصميم المعماري: Windsurf هو منتج برمجي مدعوم بالذكاء الاصطناعي أطلقه فريق Codeium، ويتم وضعه كأول "بيئة تطوير متكاملة وكيلة" (Agentic IDE) في الصناعة. على عكس Copilot، الذي يتطلب التبديل بين وضعي الدردشة/الوكيل، يمتلك مساعد الذكاء الاصطناعي في Windsurf (المسمى Cascade) قدرات وكيلية طوال الوقت، حيث ينتقل بسلاسة بين الإجابة على الأسئلة وتنفيذ المهام متعددة الخطوات بشكل مستقل حسب الحاجة. يلخص Codeium فلسفته رسميًا على أنها "التدفقات = الوكلاء + المساعدون" (Flows = Agents + Copilots). يشير "التدفق" (Flow) إلى وجود المطورين والذكاء الاصطناعي في حالة تعاون متزامنة: يوفر الذكاء الاصطناعي اقتراحات مثل المساعد في أي وقت، ويمكنه أيضًا تولي زمام الأمور بشكل استباقي وتنفيذ سلسلة من العمليات عند الحاجة، بينما تظل العملية بأكملها متزامنة في الوقت الفعلي مع عمليات المطور. لا تحتوي هذه البنية على نقاط واضحة لتبديل الأدوار بين الإنسان والآلة؛ فالذكاء الاصطناعي "يستمع" باستمرار إلى تصرفات المطور ويتكيف مع الإيقاع. عندما تدردش مع Cascade في Windsurf، يمكنه الإجابة مباشرة على أسئلتك أو تفسير عبارتك كمهمة، ثم تشغيل سلسلة من العمليات. على سبيل المثال، إذا أخبر المستخدم Cascade ببساطة في محادثة: "يرجى تنفيذ مصادقة المستخدم وتحديث أقسام التعليمات البرمجية ذات الصلة"، يمكن لـ Cascade فهم ذلك تلقائيًا كمتطلب متعدد الوحدات: سيبحث في قاعدة التعليمات البرمجية لتحديد الملفات المتعلقة بمصادقة المستخدم، ويفتح هذه الملفات ويعدلها (مثل إضافة وظائف المصادقة، وإنشاء تكوينات جديدة، وتعديل منطق الاستدعاء)، ويقوم بتشغيل اختبارات المشروع إذا لزم الأمر، وأخيرًا يبلغ المستخدم بحالة الإكمال. طوال العملية، لا يحتاج المطور إلى تبديل الأوضاع أو المطالبة خطوة بخطوة. فيما يتعلق بالتعددية الوسائطية، يركز Windsurf/Cascade حاليًا بشكل أساسي على مجال نص التعليمات البرمجية ولم يذكر بعد دعم تحليل الصور أو الصوت. ومع ذلك، فإن فهم Cascade لـ "نية المطور" لا يأتي فقط من إدخال النص النقي، بل أيضًا من إشارات مختلفة في بيئة IDE (انظر قسم السياق أدناه). بشكل عام، تتمثل الفلسفة المعمارية لـ Windsurf في دمج الذكاء الاصطناعي في بيئة IDE: التطور من أداة سلبية للإجابة على الأسئلة إلى شريك تعاوني نشط لزيادة كفاءة التطوير إلى أقصى حد.
تجزئة المهام والاستقلالية
يمتلك Cascade واحدة من أقوى قدرات التنسيق الذاتي بين المنتجات الحالية. بالنسبة للتعليمات عالية المستوى التي يقدمها المستخدم، فإنه يقوم أولاً بتحليل شامل للنية وتقييم النطاق، ثم يبدأ تلقائيًا سلسلة من الإجراءات المحددة لتحقيق الهدف. في مثال إضافة وظيفة مصادقة جديدة، قد يقوم Cascade بالخطوات الداخلية التالية: 1) مسح المشروع للعثور على الوحدات التي تحتاج إلى تعديل أو إنشاء (مثل نموذج المستخدم، خدمة المصادقة، التكوين، مكونات واجهة المستخدم، وما إلى ذلك)؛ 2) إنشاء تغييرات التعليمات البرمجية المقابلة، بما في ذلك إضافة وظائف، وتعديل الاستدعاءات، وتحديث التكوينات؛ 3) استخدام الأدوات التي يوفرها Windsurf لفتح الملفات وإدراج التعديلات؛ 4) تشغيل مجموعات الاختبار الموجودة أو بدء خادم تطوير للتحقق مما إذا كانت التغييرات الجديدة تعمل بشكل صحيح. إذا كشفت الاختبارات عن مشاكل، فلن يتوقف Cascade وينتظر التدخل البشري، بل سيستمر في تحليل الخطأ، وتحديد الخلل، وتعديل التعليمات البرمجية تلقائيًا، وتشغيل الاختبارات مرة أخرى للتحقق. يمكن أن تستمر هذه الحلقة المغلقة لعدة جولات حتى يثق Cascade بأن المهمة قد اكتملت أو يواجه عقبة لا يمكن حلها. وتجدر الإشارة إلى أن Windsurf يؤكد على إبقاء المطور على اطلاع ولكن دون إثقال كاهله بشكل مفرط. على وجه التحديد، سيعرض Cascade الاختلافات لجميع الملفات المعدلة للمستخدم بعد تنفيذ التغييرات الرئيسية، ويطلب تأكيدًا دفعة واحدة. يمكن للمستخدمين تصفح كل فرق وتحديد ما إذا كانوا سيقبلون التغييرات أو يتراجعون عنها. تضيف هذه الخطوة بشكل فعال مرحلة مراجعة بشرية بين إعادة هيكلة الذكاء الاصطناعي المستقلة وتقديم التعليمات البرمجية، دون تعطيل عمليات الذكاء الاصطناعي المستمرة بشكل مفرط أو ضمان أن النتيجة النهائية تلبي التوقعات البشرية. مقارنة بـ Cursor، الذي يتطلب من المستخدم قيادة كل خطوة، يميل Cascade في Windsurf نحو الاستقلالية الافتراضية: يذكر المستخدم ببساطة المتطلب، ويكمل الذكاء الاصطناعي جميع المهام الفرعية قدر الإمكان، ثم يسلم النتائج للمستخدم لقبولها. يستفيد وضع العمل هذا بالكامل من ميزة الذكاء الاصطناعي في التعامل مع العمليات المعقدة مع إدارة المخاطر من خلال تصميم "تأكيد نهائي".
استراتيجية استدعاء النموذج
تأتي تقنية الذكاء الاصطناعي وراء Windsurf بشكل أساسي من نماذج Codeium والبنية التحتية التي طورتها بنفسها. لقد جمعت Codeium خبرة في مجال مساعدي ترميز الذكاء الاصطناعي (يوفر مكون Codeium الإضافي ميزات إكمال شبيهة بـ Copilot)، ويُعتقد أن النموذج الذي يستخدمه Cascade هو نموذج لغة Codeium الكبير المحسن للبرمجة (ربما تم ضبطه بدقة بناءً على نماذج مفتوحة المصدر، أو دمج نماذج متعددة). يكمن الاختلاف الواضح في أن Codeium يقدم خيارات استضافة ذاتية للمستخدمين من الشركات، مما يعني أنه يمكن نشر النماذج وخدمات الاستدلال التي يستخدمها Windsurf على خوادم الشركة الخاصة. وهذا يعني من الناحية المعمارية أن Codeium لا يعتمد على واجهات برمجة تطبيقات تابعة لجهات خارجية مثل OpenAI؛ يمكن توفير نماذجه الأساسية بواسطة Codeium وتشغيلها في بيئة العميل. في الواقع، تدعم منصة Codeium مفهوم "المحركات" (Engines)، حيث يمكن للمستخدمين اختيار محرك الواجهة الخلفية للذكاء الاصطناعي، على سبيل المثال، استخدام نموذج Codeium الخاص "Sonnet" (أحد الأسماء الرمزية للنماذج الداخلية لـ Codeium) أو بديل نموذج مفتوح المصدر. يمنح هذا التصميم Windsurf نظريًا مرونة النموذج: إذا لزم الأمر، يمكنه التبديل إلى محرك نموذج مكافئ آخر، على عكس Cursor، الذي يمكنه فقط استخدام عدد قليل من النماذج الثابتة المدرجة من قبل الفريق الرسمي. ضمن التكوين الافتراضي الحالي، تأتي معظم ذكاء Windsurf من خدمات Codeium عبر الإنترنت، ويتم تنفيذ استدلاله أيضًا في السحابة. ومع ذلك، على عكس Cursor، الذي يعتمد كليًا على الخدمات البعيدة، قام Windsurf بتحسين بعض وظائف الذكاء الاصطناعي محليًا: على سبيل المثال، ميزة إكمال علامة التبويب (Supercomplete)، وفقًا للمعلومات الرسمية، مدفوعة بنموذج Codeium الصغير الذي طورته بنفسها، ويعمل بسرعة عالية على الخوادم المحلية/القريبة. وهذا يجعل الاقتراحات الفورية أثناء الترميز اليومي غير محسوسة تقريبًا من حيث زمن الوصول، بينما يتم استدعاء نماذج السحابة القوية للمحادثات المعقدة أو التوليد على نطاق واسع. بالنسبة لعملاء الشركات الذين يهتمون بأمن البيانات، فإن أكبر نقطة بيع لـ Windsurf هي دعمه للنشر "المعزول هوائيًا" (air-gapped): يمكن للشركات تثبيت محرك Codeium AI الكامل داخل جدار الحماية الخاص بها، وتبقى جميع التعليمات البرمجية وبيانات المطالبات داخل الشبكة الداخلية. لذلك، اتخذ Windsurf خيارًا معاكسًا لـ Cursor في استراتيجية نموذجه - السعي لتحقيق قدر أكبر من استقلالية النموذج ومرونة النشر، بدلاً من الاعتماد كليًا على واجهات برمجة التطبيقات لشركات الذكاء الاصطناعي الرائدة. يتطلب هذا الخيار المزيد من الاستثمار الهندسي (تدريب وصيانة النماذج الخاصة، بالإضافة إلى دعم النشر المعقد)، لكنه اكتسب اعتراف
ملخص مقارنة الأنظمة
يُقدم الجدول أدناه نظرة عامة على أوجه التشابه والاختلاف في معماريات الوكلاء (Agent) لكل من GitHub Copilot و Cursor و Windsurf:
| بُعد الميزة | GitHub Copilot | Cursor | Windsurf (Codeium) |
|---|---|---|---|
| الموقع المعماري | بدأ كبوت دردشة للمساعدة في البرمجة، وتوسع ليشمل "وضع الوكيل" (الاسم الرمزي Project Padawan)؛ يمكن تضمين الوكيل في منصة GitHub، ودمجه مع سير عمل المشكلات/طلبات السحب (Issues/PRs). محادثة متعددة الأدوار بوكيل واحد، لا توجد بنية وكلاء متعددين صريحة. يدعم الإدخال متعدد الوسائط (الصور). | محرر محلي يعتمد على الذكاء الاصطناعي أولاً (مشتق من VS Code)، يتضمن تفاعلات وضع الدردشة ووضع الوكيل. يركز وضع المساعد الافتراضي على الأسئلة والأجوبة والإكمال، ويتطلب وضع الوكيل تفعيلًا صريحًا للذكاء الاصطناعي لتنفيذ المهام بشكل مستقل. بنية وكيل واحد، لا توجد معالجة متعددة الوسائط. | مصمم منذ البداية كـ " |